事情还得从8月1日被wenku8.com的站长通知安卓app与版权公司合作说起。
那时我重做的新的wenku8安卓app刚发出1.0,也是轻国和轻文库刚分家的时候。我直接被站长告知与某公司签约合作了(目前觉得可能并非描述的那样),主要是为了获取版权,将网站上发布的轻小说洗白。因为我是三方开发者啊,并没有权利阻挠站长的决策,所以只能接受了,那时候有两个想法:
- 版权时代要来临了,要考虑盗版以后怎么办了;
- 以后做app不能只为一个网站做,要做通用接口的(也就是未来的
Project PRPR); - 我要把网站数据弄下来,至少用作app的离线数据包;
针对以上三点,我后续都采取了一些行动~
未来该怎样做网络盗版(特大误!)
我自己当时头脑发热,就在想以后盗版肯定有出路的,因为我不愿意做付费用户……(知法犯法,我懂)
于是我把目标投向了epub,而且比较了epub、mobi、txt这几种格式后发现还是epub的排版最好,而且网上已经有很多高手在做精排了,我在想匿名开个网站吧,专门收集分享精校版的epub,首先从当当读书搞起,当当读书刚出来的时候狂送代金券,我算了下总共有100多RMB的价值,所以我也存了很多当当读书弄出来的epub电子书,排版确实很不错,而且链接做的也很完善。
于是我就注册了个域名,而且SSL证书都弄好了 _(:3」∠)_ 就差我自己弄个前端和后端出来了,但是当时不是要考研嘛,就先搁置了,用我的阿里云ECS把kgbook的所有epub资源先下载下来了,嘎嘎,总共2G多,用的是PHP CLI抓取的,用的是如下的脚本:
<?php
function getFromNetForever($url, $time = 10) {
$html = "";
while(1) {
if(($html = file_get_contents($url)) !== FALSE)
break;
if(-- $time <= 0)
return FALSE;
echo "Failed in '$url', time $time, sleep 5s.\n";
sleep(5);
}
return $html;
}
$dbBook = "book.db";
if (!file_exists($dbBook)) {
if (!($fp = fopen($dbBook, "w+"))) {
exit(error_code(-1, LN));
}
fclose($fp);
// create table
$db = new PDO("sqlite:book.db");
$db->exec("create table book(id integer, name text, author text, type text, info text, image text);"); // base64 image
$db = null;
}
for($idx = 1; $idx <= 67; $idx ++) {
// get content
$url = 'http://www.kgbook.com/list/index' . ($idx == 1 ? '' : '_' . $idx) . '.html';
$html = '';
if(($html = getFromNetForever($url)) === FALSE) {
continue;
}
// filter url
$index = $end = $count = 0;
while(1) {
$index = strpos($html, '<h3 class="list-title">', $end ) + 23;
$index = strpos($html, '"', $index) + 1;
if(!$index || $index < $end) break;
$end = strpos($html, '"', $index);
if($end - $index < 0) break;
$novelURL = substr($html, $index, $end - $index);
if($novelURL[0] == '/') $novelURL = "http://kgbook.com" . $novelURL;
echo $novelURL . "\n";
$index = $end;
// loop for content and download
$novelInfo = '';
if(($novelInfo = getFromNetForever($novelURL)) !== FALSE) {
// get id
$idBeg = strrpos($novelURL, '/') + 1;
$id = substr($novelURL, $idBeg, strrpos($novelURL, '.') - $idBeg);
// get type
$typeBeg = strrpos(substr($novelURL, 0, $idBeg - 1), '/') + 1;
$type = substr($novelURL, $typeBeg, $idBeg - 1 - $typeBeg);
// get name
$nameBeg = strpos($novelInfo, 'class="news_title"') + 19;
$name = substr($novelInfo, $nameBeg, strpos($novelInfo, '</h1>', $nameBeg) - $nameBeg);
// get image
$imageBeg = strpos($novelInfo, 'src="', $nameBeg) + 5;
$image = "http://www.kgbook.com" . substr($novelInfo, $imageBeg, strpos($novelInfo, "\"", $imageBeg) - $imageBeg);
// get author
$authorBeg = strpos($novelInfo, '<li>作者:') + 4 + strlen('作者:');
$author = substr($novelInfo, $authorBeg, strpos($novelInfo, '</li>', $authorBeg) - $authorBeg);
// get info
$infoBeg = strpos($novelInfo, '<h3>简介:</h3><p>') + 12 + strlen('简介:');
$info = str_replace(array("\r\n", "\r", "\n", "<br />"), "\\n", substr($novelInfo, $infoBeg, strpos($novelInfo, '</p>', $infoBeg) - $infoBeg));
$info = str_replace("\\n\\n", "\\n", $info);
$info = str_replace("\\n\\n", "\\n", $info);
// get image source
$imageSrc = getFromNetForever($image);
$imageContent = base64_encode($imageSrc === FALSE ? "" : $imageSrc);
$db = new PDO("sqlite:book.db");
$db->exec("insert into book values (" . addslashes($id) .",'" . addslashes($type) . "','"
. addslashes($name) . "','" . addslashes($author) . "','" . addslashes($info) . "','$imageContent');");
$db = null;
// download
$dlBeg = $dlEnd = 0;
while(1) {
// get download url
$dlBeg = strpos($novelInfo, 'DownSys', $dlEnd) - 20;
if($dlBeg < $dlEnd) break;
$dlEnd = strpos($novelInfo, "\"", $dlBeg);
if($dlBeg > $dlEnd) reak;
$dlLink = substr($novelInfo, $dlBeg, $dlEnd - $dlBeg);
$dlLink = str_replace("&", "&", $dlLink);
// get download type
$dlType = substr($novelInfo, $dlEnd + 2, strpos($novelInfo, "</a>", $dlEnd) - ($dlEnd + 2));
echo $dlLink . "\n";
system("wget -N -O \"dl/" . $id . "." . $dlType . "\" \"" . $dlLink . "\"");
}
}
else
echo "error load: $novelURL\n";
}
}
$db = null;
?>
正则表达式不熟啊,所以就没用正则了,让大触们见笑了~
抓取完之后整个网站的数据都存在了book.db这个SQLite数据库里面,包括封面、作者等信息,总共10M多,作为基础数据是很不错的了。
不得不说PHP写脚本真心方便啊,服务器一直挂机就行了,下载好自动退出。
不过由于这几天发生的版权的事,我也打消了建立盗版电子书网站的念头……
虽然我SSL申请账号是Gmail、虽然我的域名注册在Namesilo,我的联系信箱也是Gmail,但是谷歌还是要回来的,还是要被审查的,说进大牢就进大牢了,我还年轻,我怕,及时打住虽然浪费钱了,但是当花钱保平安好了。因为我想建这个站的目的还是有盈利的想法的,类似于程序员联合开发网这样的下载机制,盈利点就不说了~
通用接口的APP是啥
在app被告知要作废的时候,我就在考虑通过html解析的方式帮lightnovel.cn弄个app出来,因为他这边lknovel.cn没有和所谓的有版权的公司合作,而linovel.com和wenku8.com都是说“有版权”了,于是我就一直在论坛私信LEO,希望能合作推出新的app,只不过没收到回信就是了~
所以我这边赶紧将app全部开源,发挥一些余热,并且把文档稍微弄一下,因为没文档的源码项目基本上是没人关注的。
我在文档里面写了一种通用解决方案:
目前 wenku8 的书目2000不到,也就是说aid是4位数; linovel 、 lknovel 的aid也都是4位数,而且都没有 wenku8 的大,所以:
在aid方面,可以采取aid+10000000的方式,比如linovel的aid是+1000万,lknovel的aid是+2000万,这样本地书架的内容就错开了。
就是强行兼容wenku8的数据格式,算是一种兼容的设计吧,非常不科学,但是可以救急,嘎嘎……最近在看重构,像这种情况肯定要重构的,一到多的扩展,本地存储的数据格式首先要重构一下,这是题外话了~
虫虫特工队
嗯,这个数字化的时代,数据无价!
所以备份数据人人有责。之前8月的时候我觉得linovel的插图不错,我就用自动化软件爬取了这个网站20G的网页+图片,结果NTFS直接挂了……囧!
原因很简单,网站的router本来就不该用文件系统做类似于NOSQL的存储,而是应该存到数据库里,经量少给文件系统增加负担。
当时用的是HTTrack Website Copier这个免费软件,而且主要目的是收集好数据自动化生成app的补丁包,提高用户体验。
结果一直风平浪静到这个月初,因为要安装OpenSUSE我就把全盘格了 =。= 结果月底就出事,真是出乎意料。
于是我又去扒wenku8的数据,这下子狠下心,ECS和本机一起扒,而且不断改进功能,最终全部爬取完成,倍感欣慰,以后可以用这些数据自动生成epub了,因为下一个项目是纯阅读器——Project PRPR!
抓取zip包
这个简单,直接写一个匹配就行了,但是处于跨平台的考虑(本机win10,ECS是RedHat),我直接用Excel填充柄拖了个地址列表,如:
wget -N -O "dl/1.zip" "http://xxxx/d.php?t=zip&id=1"
wget -N -O "dl/2.zip" "http://xxxx/d.php?t=zip&id=2"
wget -N -O "dl/3.zip" "http://xxxx/d.php?t=zip&id=3"
wget -N -O "dl/4.zip" "http://xxxx/d.php?t=zip&id=4"
wget -N -O "dl/5.zip" "http://xxxx/d.php?t=zip&id=5"
这样的话Linux和windows都可以兼容啦!于是就下载了一堆zip。
下载zip的好处相比于txt在于可以看到目录,而且章节分明~
下载图片
由于zip包中不含有图片,所以我需要遍历每一个章节,寻找里面的图片,然后下载下来。
由于之前FS崩溃的经验,我这次采取的是一个小说的图片放到同一个压缩包里面,于是处理压缩包哪家强?Python赛高!
代码原型机
# -*- coding:utf-8 -*-
# Usage:
# python dimg.py
# python dimg.py 10.zip # run from 10.zip
import zipfile, os, sys, urllib.request as ur, socket
#init
zipFolder = 'dl'
saveFolder = 'imgs'
if not os.path.exists(zipFolder + os.sep + saveFolder):
os.mkdir(zipFolder + os.sep + saveFolder)
matcher = 'http://xxxx'
socket.setdefaulttimeout(15)
# get command line arg to continue from a specific file
canBegin = True
if len(sys.argv) == 2:
canBegin = False # jump to the file first
# go through all the file in target folder
lstFile = [f for f in os.listdir(zipFolder) if os.path.isfile(os.path.join(zipFolder, f))]
for fileName in lstFile:
# jump to the start file
if not canBegin:
if fileName != sys.argv[1]:
print('# pass the file: ' + fileName)
continue
else:
canBegin = True
# open .zip file
tempName = zipFolder + os.sep + fileName
zf = zipfile.ZipFile(tempName, 'r') # in file
zout = zipfile.ZipFile(zipFolder + os.sep + saveFolder + os.sep + fileName.replace('.', '-img.'), 'w')
print('# Processing file: ' + fileName + ':')
# go through all file in
for name in zf.namelist():
if name.find('.htm') == -1: continue
content = str(zf.read(name))
print(' # Processing file: ' + name + ':')
# find all links
beg = 0
lastImage = ''
while content.find(matcher, beg) != -1:
inBeg = content.find(matcher, beg)
inEnd = content.find('"', inBeg)
url = content[inBeg:inEnd]
beg = inEnd # for next loop
if url == lastImage:
continue # skip
print(' Fetching ' + url + '...')
# begin request
while True:
try:
f = ur.urlopen(url)
b = f.read()
except Exception as e:
print(e)
print(' !!redo ->' + name)
continue
# add to zip archive
zout.writestr(url[url.find('pictures'):], b)
break
print(' -> Done')
lastImage = url
print(' Done the file: ' + name)
zout.close()
zf.close();
print('- Done the file: ' + zipFolder + os.sep + saveFolder + os.sep + fileName.replace('\.', '-img.'))
这个代码单线程,加入了网络异常自动重连的功能,提供了一个按顺序下载的方法,由于是控制太,可以手动退出,所以在退出的时候可以看到哪个文件未完成,所以提供了另一个用于续传的方法,命令行参数第二个是x.zip这样的,用于从该文件开始继续下载。
改进:缺啥补啥
这次改动主要就是添加了一个判断文件是否存在,以及一些细微的调节。
if os.path.exists(tempImageName):
print('# Passed ' + tempImageName)
continue
这段代码需要自己处理未完成的文件,不过可以自动补齐不存在的文件,更加自动。而且列举path这样的工作具有一定随机性,所以这样也更方便。
改进:多线程
下载真的超级慢啊,受不了了,本来以为服务器响应可以给力些,但是由于机身在大洋彼岸,还是决定使用多线程。
那么问题来了,如何多线程啊,于是去找了python3的多线程使用方法,有点绕,因为各个版本区别蛮大的,然后引入Queue这个具有多线程同步的数据结构来辅助我:
# init
zipFolder = 'dl'
saveFolder = 'imgs'
maxThread = 4
if not os.path.exists(zipFolder + os.sep + saveFolder):
os.mkdir(zipFolder + os.sep + saveFolder)
matcher = 'http://xxxx'
socket.setdefaulttimeout(15)
def worker():
while True:
fileName = q.get()
# do fetching data, open .zip file
tempName = zipFolder + os.sep + fileName
tempImageName = zipFolder + os.sep + saveFolder + os.sep + fileName.replace('.', '-img.')
if os.path.exists(tempImageName):
print('# Passed ' + tempImageName)
continue
zf = zipfile.ZipFile(tempName, 'r') # in file
zout = zipfile.ZipFile(tempImageName, 'w')
print('# Processing ' + fileName + ' (' + threading.current_thread().name + ')')
# go through all file in
for name in zf.namelist():
if name.find('.htm') == -1:
continue # skip non-htm file, like: *.css
content = str(zf.read(name))
# find all links
beg = 0
lastImage = ''
while content.find(matcher, beg) != -1:
inBeg = content.find(matcher, beg)
inEnd = content.find('"', inBeg)
url = content[inBeg:inEnd]
beg = inEnd # for next loop
if url == lastImage:
continue # skip downloaded file like this: <a><img/></a>
# begin request
while True:
try:
f = ur.urlopen(url)
b = f.read()
except Exception as e:
print(e)
#print(' !!Redo')
continue
# add to zip archive
zout.writestr(url[url.find('pictures'):], b)
break
lastImage = url
zout.close()
zf.close()
print('- Done the file: ' + tempImageName + ' (' + threading.current_thread().name + ')')
q.task_done()
# create threads
q = Queue()
for i in range(maxThread):
print('creating: ' + str(i))
t = threading.Thread(target=worker)
t.daemon = True # thread dies when main thread (only non-daemon thread) exits.
t.start()
# fill queue
lstFile = [f for f in os.listdir(zipFolder) if os.path.isfile(os.path.join(zipFolder, f))]
for item in lstFile:
q.put(item)
q.join() # wait for ending
多线程果然快太多了!不过处于保护,我还是将网址隐去了~
这边是程序的输出,自带pass功能:
# Passed dl\imgs\979-img.zip
# Passed dl\imgs\98-img.zip
# Processing 980.zip (Thread-1)
<urlopen error timed out>
- Done the file: dl\imgs\980-img.zip (Thread-1)
# Processing 981.zip (Thread-1)
- Done the file: dl\imgs\981-img.zip (Thread-1)
# Processing 982.zip (Thread-1)
- Done the file: dl\imgs\982-img.zip (Thread-1)
# Passed dl\imgs\983-img.zip
# Processing 984.zip (Thread-1)
- Done the file: dl\imgs\96-img.zip (Thread-2)
# Processing 992.zip (Thread-2)
- Done the file: dl\imgs\992-img.zip (Thread-2)
# Processing 993.zip (Thread-2)
- Done the file: dl\imgs\984-img.zip (Thread-1)
# Processing 994.zip (Thread-1)
- Done the file: dl\imgs\994-img.zip (Thread-1)
# Passed dl\imgs\995-img.zip
# Processing 996.zip (Thread-1)
- Done the file: dl\imgs\993-img.zip (Thread-2)
# Passed dl\imgs\997-img.zip
# Processing 998.zip (Thread-2)
- Done the file: dl\imgs\978-img.zip (Thread-3)
# Processing 999.zip (Thread-3)
- Done the file: dl\imgs\97-img.zip (Thread-4)
timed out
- Done the file: dl\imgs\998-img.zip (Thread-2)
- Done the file: dl\imgs\999-img.zip (Thread-3)
- Done the file: dl\imgs\996-img.zip (Thread-1)
全部下载完毕之后是2011个zip图包,拿WinRAR检测一下是否有误(如果是异常中止的话是无法测试通过的):
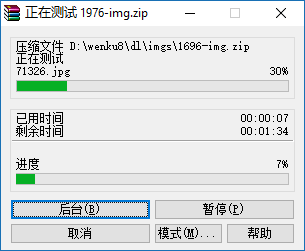
2000多个包测试完真是长吁一口气,总共10G。
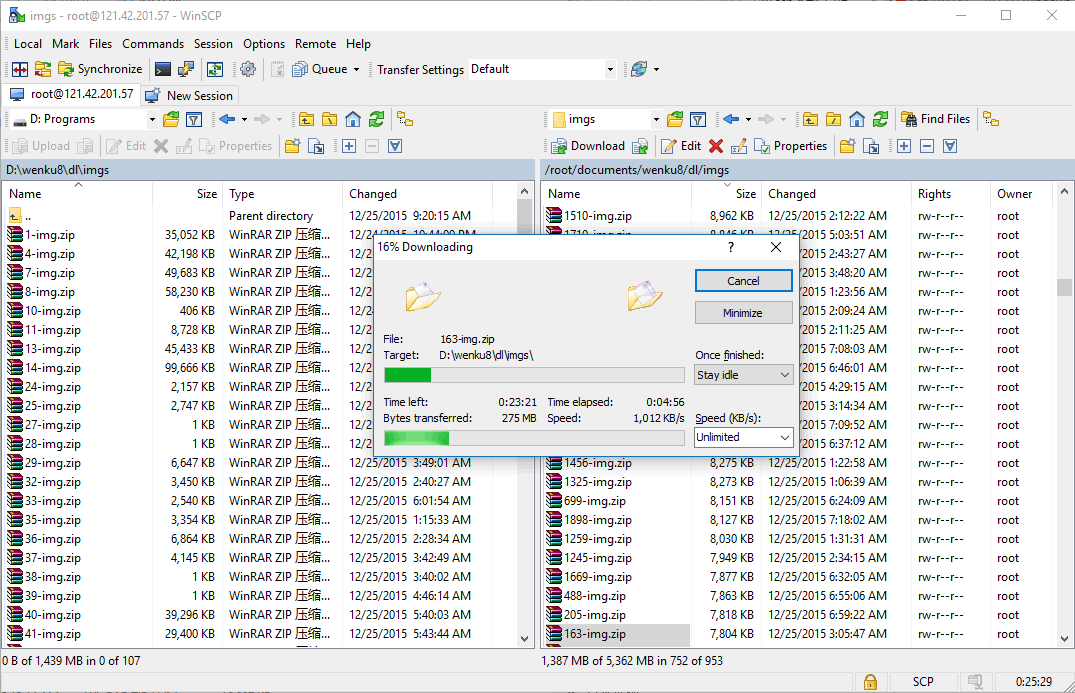
以及服务器帮我下载的一些包,直接SCP拷贝(这边Git自带的SCP一启动就crash,只得寻求他法):
这文章大概烂尾了 23333